引言:被遗忘的“声音金矿”
在企业的数字化资产中,音频数据(如会议录音、客服通话、技术培训)往往占据了巨大的存储空间,但其利用率却极低。即便在2026年,许多企业依然把语音转写看作是“把录音变成文字”的搬运工。然而,在以大模型为核心的AI 2.0时代,文字只是起点,知识才是终点。
随着RAG(Retrieval-Augmented Generation,检索增强生成)技术的成熟,灵声智库率先提出并实现了“语音转写 + 向量化引擎 + RAG”的闭环链路,将海量非结构化的音频实时转化为可搜索、可管理、可生成的企业级知识大脑。
一、 核心痛点:为什么“仅有文本”是不够的?
在传统的语音转写工作流中,即便识别率达到99%,依然面临以下三大痛点:
1. 信息密度极低(Information Noise)
1小时的会议可能转写出15,000字的文本,但其中包含大量口头禅、重复性废话和无效讨论。人工提取核心结论依然费时费力。
2. 检索粒度粗糙(Indexing Gap)
传统的全文检索(Keyword Search)很难处理语义上的关联。比如搜索“设备维修方法”,如果会议中说的是“那个冷凝器的排查手顺”,关键词无法匹配。
3. 数据时效性断层(Static Content)
企业的知识库往往依赖于员工手动录入的文档,而最真实、最前沿的技术探讨往往发生在即时的语音交流中。这种“声音到知识”的链条断裂,导致企业错失了大量隐性经验。
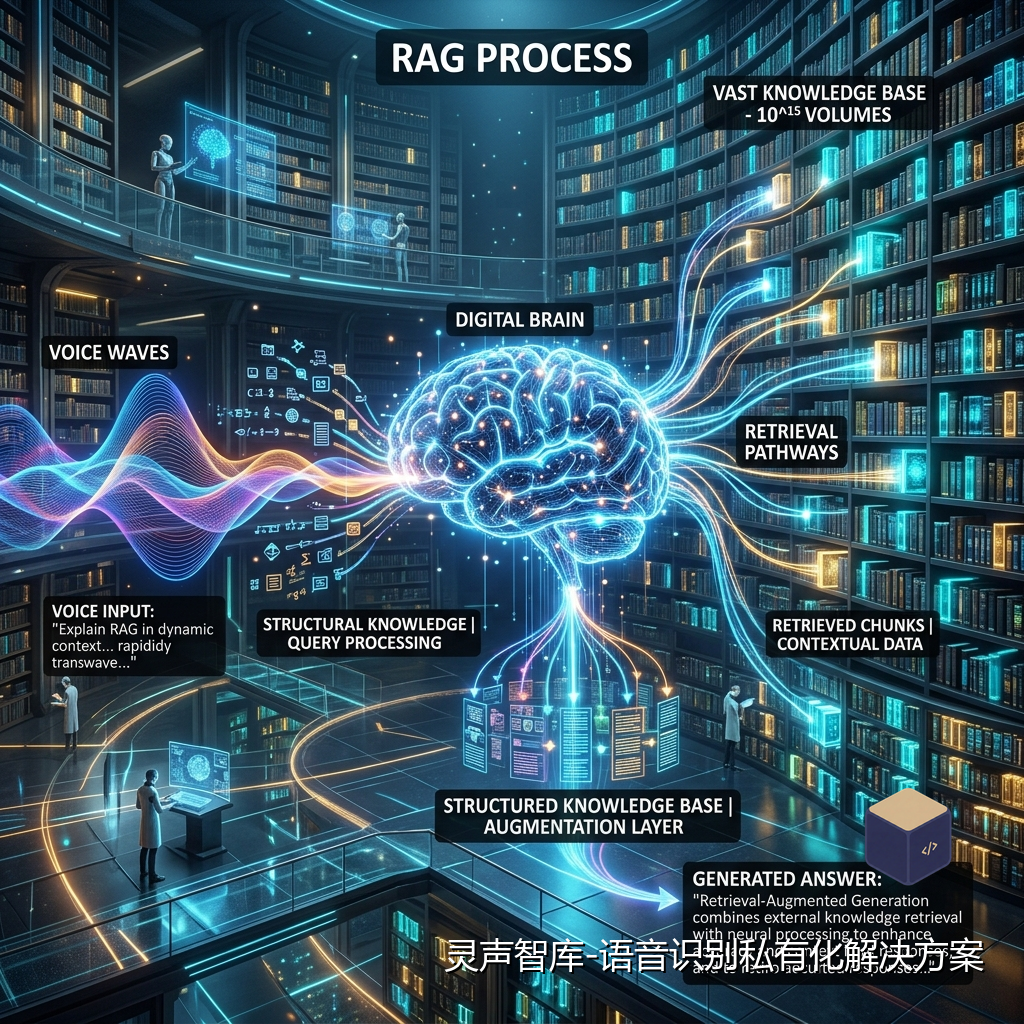
二、 灵声智库的“语义化”转型:ASR + RAG 的三部曲
为了激活这些“声音金矿”,灵声智库在私有化部署架构中深度集成了语义增强套件。
1. 第一步:高精度的长音频语义分段
灵声智库不再是盲目地按句号切分,而是通过分析语调起伏与上下文语义,自动将转写出的长文本划分为具备单一主题的“语义块(Chunks)”。这种精准的切片是后续RAG检索精度的基石。
2. 第二步:本地化向量嵌入与知识注入
在私有化环境中,转写出的语义块会被实时推送到灵声智库集成的国产轻量级向量模型中。系统会自动为每一段音频生成多维度的语义特征,并与其对应的音频时间戳、发言人声纹、会议背景信息进行多模态关联,存入内网的向量数据库。
3. 第三步:基于检索的实时生成与问答
通过与私有化大模型对接,即使面对数万小时的历史音频,员工也只需通过自然语言提问:“去年关于二期工程的预算争论点在哪里?”系统会实时回溯、检索、总结,并精准定位到那几秒钟的原始录音。
三、 实战场景:灵声智库 ASR+RAG 的典型应用
2026年,这类复合型技术已在多个行业催生出全新的效率工具。
1. 智能客服的“上帝视角”
客服主管不再需要听取海量的录音,只需通过系统生成的“实时舆情分析”,就能根据今天所有通话的语义汇总,快速发现某款产品的新型共性缺陷。
2. 研发机构的“永不遗忘”
每一个技术评审会的语音都会被自动转化为知识切片。当新入职的工程师询问“为何这个接口不采用异步模式”时,系统会自动重现半年前评审会议上关于此点的一分钟录音片段。
四、 效益实测:从转录到决策的闭环测试
我们在某大型制造企业的研发中心进行了为期一个月的对比测试:
| 测试项目 | 纯语音转写模式 (ASR) | 灵声智库 ASR + RAG 模式 | 效率提升率 |
|---|---|---|---|
| 关键决策点回溯时长 | 平均 45 分钟 (手动翻阅) | 8 秒 (语义搜索) | 提升 300 倍 |
| 会议摘要生成准确率 | 人工总结,误差较大 | AI 基于原文生成,高保真 | 显著提升 |
| 隐性知识留存率 | 随人员离职流失 | 100% 数字化沉淀 | 质的飞跃 |
| 跨会议关联发现 | 极难 (点状信息) | 自动关联相同主题讨论 | 新增能力 |
五、 结语:让企业在“声音”中建立智慧堡垒
2026年的数字化共识是:数据是石油,而AI是炼油厂。灵声智库通过将私有化语音转写赋予RAG的灵魂,成功将原本沉睡在服务器角落的音频文件,炼化成了实时可用的智慧动力。
我们不仅在录音,更是在为您的企业记录“集思广益”的每一个瞬间。了解更多关于语音大模型与RAG融合的前瞻方案,请访问灵声智库。
背景技术:向量化索引、语义纠错、实时推理优化、私有化合规。 2026年4月4日